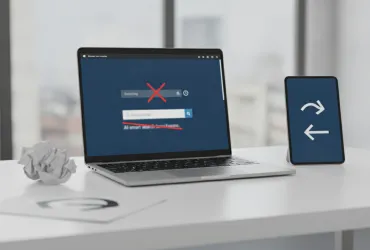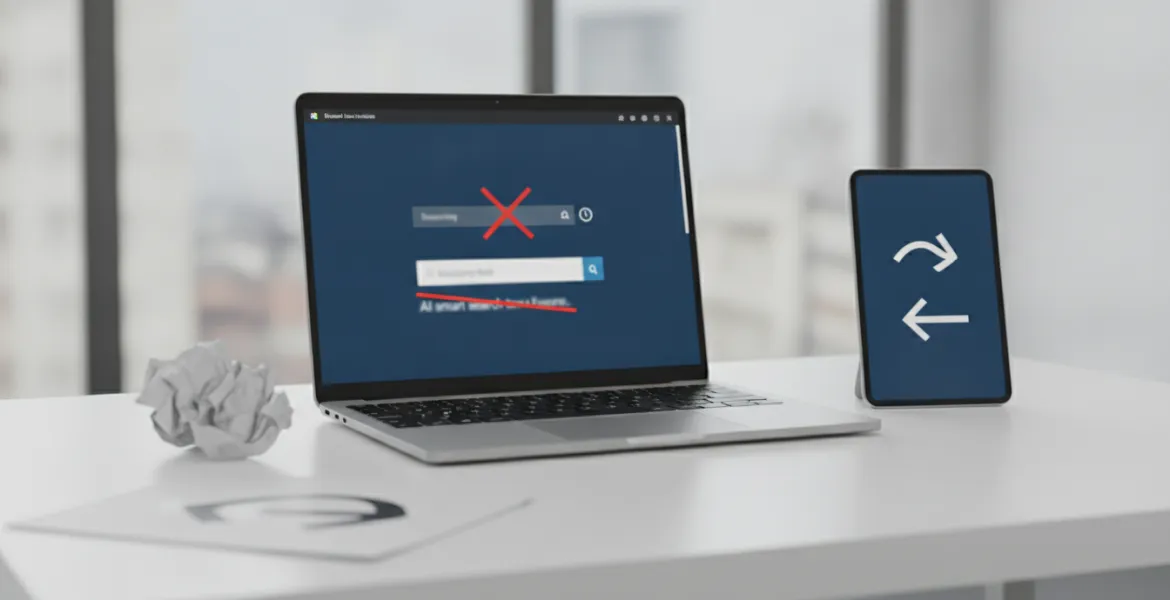
La tecnologia alla base di questa funzione di Edge mirava a creare un'indicizzazione semantica dei siti visitati, consentendo di ritrovare informazioni basandosi sul concetto piuttosto che sulla stringa di testo esatta. Ad esempio, se un utente avesse voluto recuperare un portale di notizie finanziarie consultato settimane prima ma di cui non ricordava il nome, avrebbe potuto semplicemente digitare 'dove ho letto i grafici sulla borsa di lunedì scorso'. Sebbene Microsoft avesse garantito che l'intera operazione avvenisse localmente sul dispositivo, senza inviare dati sensibili ai server cloud, l'accoglienza del pubblico è stata gelida. Molti utenti hanno manifestato una crescente preoccupazione per la propria privacy, descrivendo l'idea di un browser che analizza e comprende ogni pagina visitata come qualcosa di decisamente inquietante, termine spesso riassunto nel dibattito online con l'aggettivo 'creepy'.
Le resistenze non sono arrivate solo dal settore consumer, ma anche dal mondo aziendale. Gli amministratori IT avevano espresso forti dubbi sulla sicurezza di una simile funzione, temendo che l'indicizzazione automatica potesse esporre dati aziendali riservati o creare nuovi vettori di attacco. Per rispondere a queste esigenze, Microsoft aveva inizialmente previsto una policy specifica, denominata EdgeHistoryAISearchEnabled, che permetteva alle organizzazioni di disabilitare centralmente lo strumento. Tuttavia, la pressione derivante dai feedback negativi e la scarsa adozione reale hanno spinto il colosso tecnologico a rivalutare l'intero progetto. In un contesto come quello del 2026, dove la trasparenza e la sovranità dei dati sono diventate priorità assolute per i consumatori globali, l'introduzione di strumenti percepiti come invadenti rischia di danneggiare la reputazione del marchio più di quanto i benefici tecnici possano giustificarne l'esistenza.
L'abbandono della ricerca IA nella cronologia di Edge non è un caso isolato, ma si inserisce in un trend più ampio di 'AI fatigue' o stanchezza da intelligenza artificiale. Negli ultimi anni, le grandi aziende tecnologiche hanno cercato di inserire algoritmi di apprendimento automatico in ogni angolo dei loro software, spesso senza una reale richiesta da parte della base utenti. Il flop di questa iniziativa ricorda da vicino le polemiche scaturite da altre funzioni simili, come Windows Recall, evidenziando come la linea di confine tra assistenza proattiva e sorveglianza digitale sia estremamente sottile. La decisione di Microsoft di fare un passo indietro dimostra una maturazione del mercato: l'innovazione deve essere accompagnata dal consenso e da un valore d'uso indiscutibile per essere accettata su larga scala.
Mentre i competitor come Google Chrome e Apple Safari continuano a esplorare l'uso dell'IA con approcci più cauti e mirati, Microsoft sembra intenzionata a ricalibrare i propri sforzi verso funzionalità che non tocchino la sfera sensibile dei dati storici di navigazione in modo così diretto. Il ritorno ai metodi di ricerca tradizionali all'interno di Edge non deve essere visto come un fallimento tecnologico, ma come una vittoria per la centralità dell'utente e per il diritto alla riservatezza. Il futuro della navigazione web nel 2026 si preannuncia quindi più bilanciato, con un'intelligenza artificiale che agisce dietro le quinte per migliorare le performance e la sicurezza, piuttosto che porsi come un osservatore onnisciente delle nostre attività quotidiane online.
In ultima analisi, il caso della versione 138 di Edge rimarrà un esempio significativo nei manuali di product management su come la percezione pubblica possa determinare il successo o il fallimento di una tecnologia all'avanguardia. La lezione per Redmond è chiara: la potenza di calcolo non può sostituire la fiducia. Per riconquistare gli utenti più scettici, l'azienda dovrà ora dimostrare che il rispetto della privacy non è solo uno slogan, ma un principio cardine che guida ogni fase dello sviluppo software, rinunciando se necessario a funzioni innovative ma eccessivamente polarizzanti.